Abstract
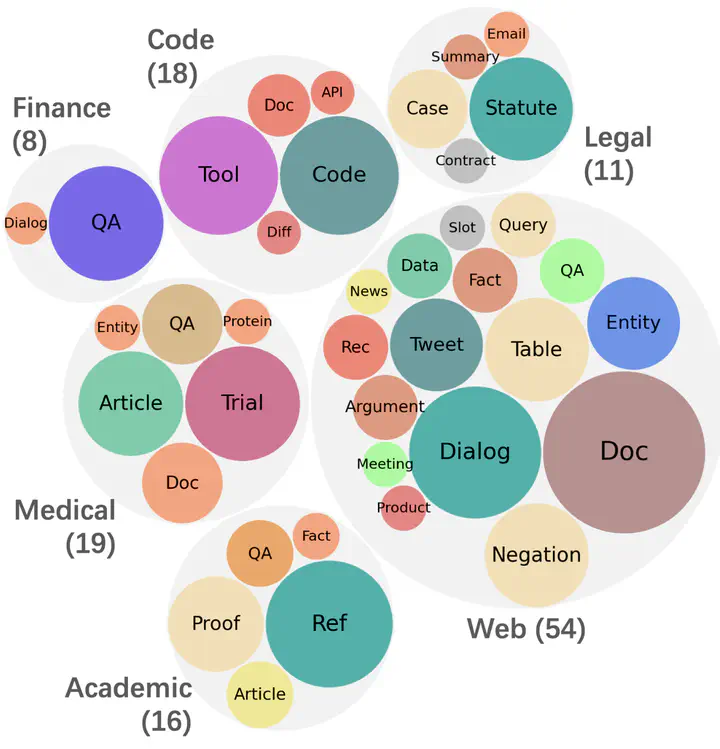
Recent information retrieval (IR) models are pre-trained and instruction-tuned on massive datasets and tasks, enabling them to perform well on a wide range of tasks and potentially generalize to unseen tasks with instructions. However, existing IR benchmarks focus on a limited scope of tasks, making them insufficient for evaluating the latest IR models. In this paper, we propose MAIR (Massive Instructed Retrieval Benchmark), a heterogeneous IR benchmark that includes 126 distinct IR tasks across 6 domains, collected from existing datasets. We benchmark state-of-the-art instruction-tuned text embedding models and re-ranking models. Our experiments reveal that instructiontuned models generally achieve superior performance compared to non-instruction-tuned models on MAIR. Additionally, our results suggest that current instruction-tuned text embedding models and re-ranking models still lack effectiveness in specific long-tail tasks. MAIR is publicly available at https://github.com/sunnweiwei/Mair