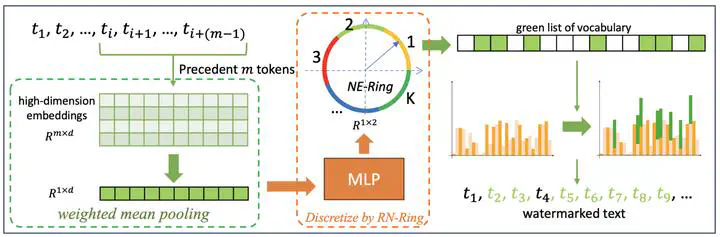
Abstract
Large language models (LLMs) have show great ability in various natural language tasks. However, there are concerns that LLMs are possible to be used improperly or even illegally. To prevent the malicious usage of LLMs, detecting LLM-generated text becomes crucial in the deployment of LLM applications. Watermarking is an effective strategy to detect the LLM-generated content by encoding a pre-defined secret watermark to facilitate the detection process. However, the majority of existing watermark methods leverage the simple hashes of precedent tokens to partition vocabulary. Such watermark can be easily eliminated by paraphrase and correspondingly the detection effectiveness will be greatly compromised. Thus, to enhance the robustness against paraphrase, we propose a semantics-based watermark framework SemaMark. It leverages the semantics as an alternative to simple hashes of tokens since the paraphrase will likely preserve the semantic meaning of the sentences. Comprehensive experiments are conducted to demonstrate the effectiveness and robustness of SemaMark under different paraphrases.