Biography
I am currently a research scientist of Search Science team at Baidu Inc, working on language model based search with Dr. Dawei Yin and Dr. Shuaiqiang Wang.
My recent research interests include: 1) Information Retrivial and Knowledge Discovery; 2) Large Language Models; 3) LLM for IR/KD;
Prospective Interns. I am actively seeking self-motivated Ph.D. students as interns in Baidu Search. If you are interested in information retrieval or pre-trained language models, please feel free to drop me an email.
If you’re a PhD student or just starting out in your career, I’m totally down to chat. Hoping to help others avoid some of the shitty things I’ve been through.
Recent Papers
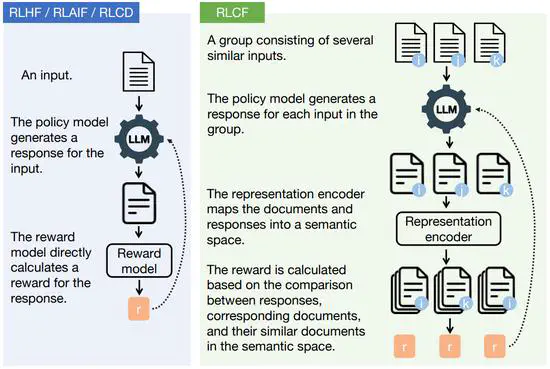
Aligning the Capabilities of Large Language Models with the Context of Information Retrieval via Contrastive Feedback
We propose an unsupervised alignment method, namely Reinforcement Learning from Contrastive Feedback (RLCF), empowering LLMs to generate both high-quality and context-specific responses.
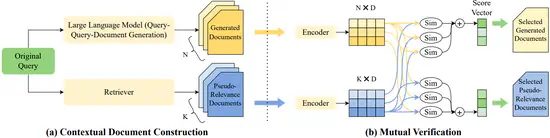
Mill: Mutual Verification with Large Language Models for Zero-shot Query Expansion
We propose a novel zero-shot query expansion framework utilizing both LLM-generated and retrieved documents.
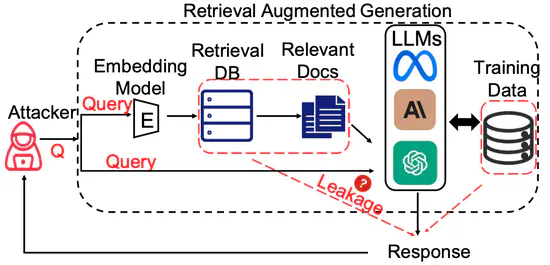
The Good and The Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG)
We conduct extensive empirical studies with novel attack methods, which demonstrate the vulnerability of RAG systems on leaking the private retrieval database. We further reveal that RAG can mitigate the leakage of the LLMs’ training data.
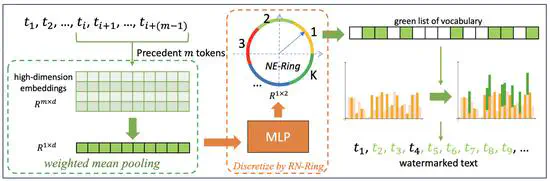
A Robust Semantics-based Watermark for Large Language Model against Paraphrasing
We propose a semantics-based watermark framework SemaMark. It leverages the semantics as an alternative to simple hashes of tokens since the paraphrase will likely preserve the semantic meaning of the sentences.
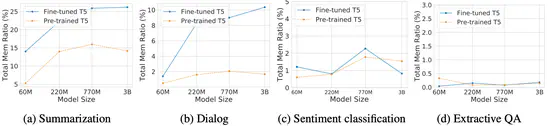
Exploring Memorization in Fine-tuned Language Models
We conduct the first comprehensive analysis to explore language models’ (LMs) memorization during fine-tuning across tasks. Our studies indicate that memorization presents a strong disparity among different finetuning tasks.
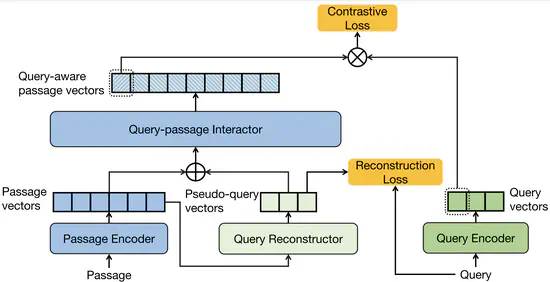
I3 Retriever: Incorporating Implicit Interaction in Pre-trained Language Models for Passage Retrieval
We incorporate implicit interaction into dual-encoders, and propose I^3 retriever. In particular, our implicit interaction paradigm leverages generated pseudo-queries to simulate query-passage interaction, which jointly optimizes with query and passage encoders in an end-to-end manner.